Reimagining Chain-of-Thought
TLDR: I trained a model to reason in symbols. It performed pretty well and was more efficient. Project repo and full writeup here.
The Hypothesis
When I first learned about chain-of-thought (CoT) reasoning1 for LLMs, I was both impressed and surprised. Impressed, because of all the cool new capabilities this technique seemingly unlocked. Surprised, because a part of me felt that the technique went against the conventional wisdom of deep learning. I thought that the whole promise of deep neural networks was that we could stop explicitly hand-crafting features, and instead leverage computation to create learned, often incomprehensible representations2. Why are we then teaching these massive black box models to reason in words just like us?
There’s plenty interesting research that explores this tension, specifically the questions of 1) what specific bottlenecks CoT is addressing and 2) are there other ways to address these bottlenecks. A needlessly mathematical way of framing CoT involves decomposing the likelihood into a conditional probability:
where represents an input question, represents the final answer, represents an intermediate reasoning chain, is the space of all possible reasoning chains, and denotes the model parameters. In other words, a model’s probability of outputting a good response sums over all possible intermediate reasoning chains; to train a good model, we need to encourage the model to output those specific reasoning steps (granted, this space is intractably large) that let it arrive at the desired answer.
There are many interesting design choices to be made when it comes to teaching a model how to output the “best” intermediate reasoning chains. DeepSeek-R1, for example, was trained with an explicit language consistency reward to prevent language mixing in its reasoning chains3. It also relied on curated readable reasoning data as a cold-start prior to reinforcement learning to ground reasoning clarity. Through ablation studies, researchers note a “slight degradation in model performance” in exchange for greater human preference alignment. This begs the question of whether we are handicapping model reasoning capabilities by enforcing a kind of readability/interpretability/sense-making constraint onto reasoning chains.
The Experiment
My initial idea was: what if we dropped the reasoning language constraint entirely, and let the model reason freely in a kind of non-linear latent space? This would involve quite a bit of model architecture redesign, which felt a little too ambitious4. Okay, what if we stuck to the autoregressive textual token generation, but relaxed the language and comprehensibility requirements? Perhaps the model could spend less time worrying about grammar, semantic structure, and general lucidity, and instead focus more on solving the question at hand, leading to higher reasoning efficiency and accuracy.
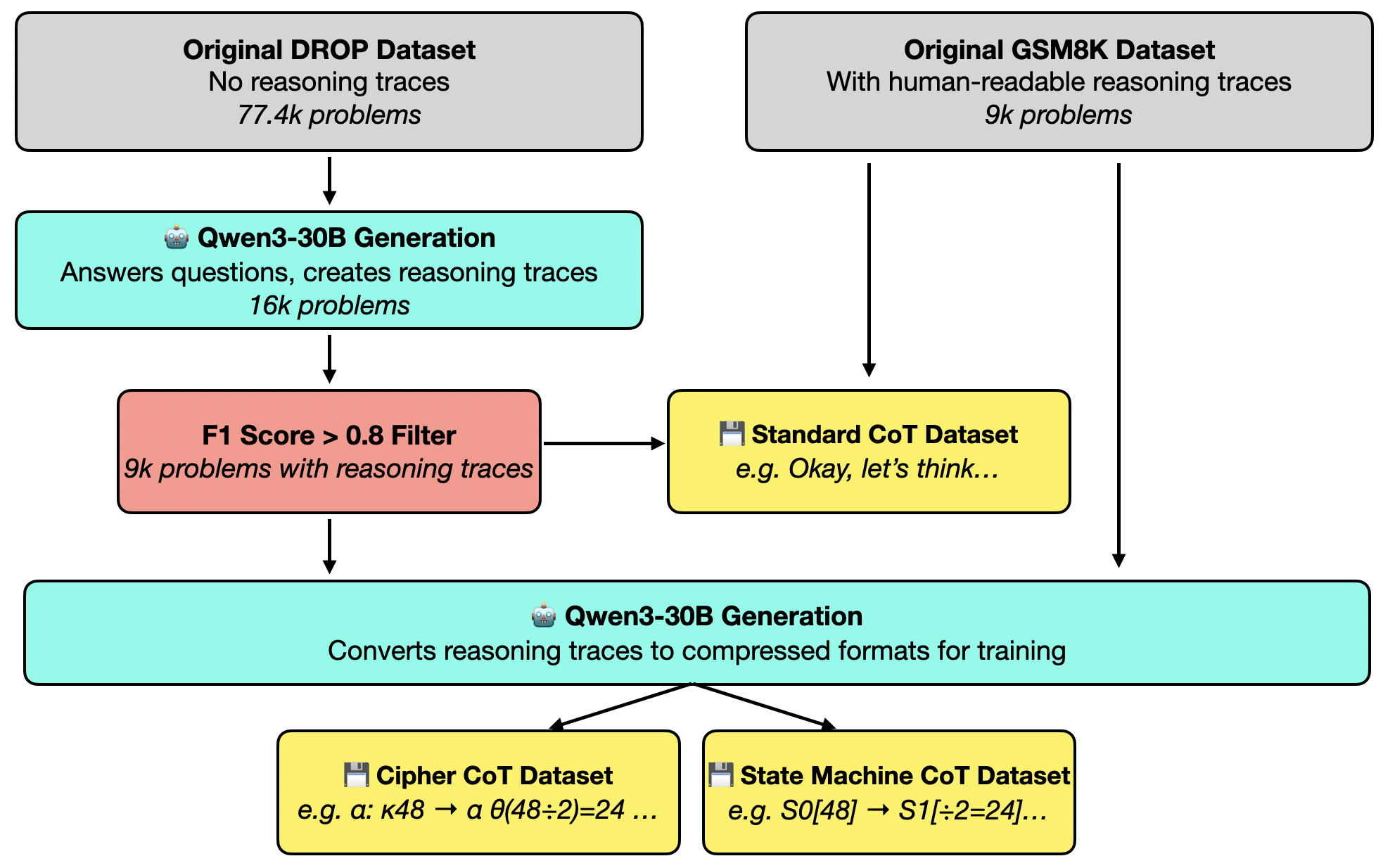
To test this idea, I came up with two alternative symbol-based “languages” with which the model, Qwen3-8B, is taught to reason. These were called Cipher — where semantic-like tokens are mapped to Greek letters — and State Machine — where reasoning is represented as transitions between abstract states. Two datasets were used to quantify reasoning capabilities: Grade School Math 8K (GSM8K), for mathematical reasoning, and Discrete Reasoning over Paragraphs (DROP), for reading comprehension.
For example: consider the GSM8K question “Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?”. The original reasoning, provided by the dataset, goes:
Natalia sold 48/2 = 24 clips in May. Natalia sold 48+24 = 72 clips altogether in April and May.
Cipher would compress this into: α: κ48 → α θ(48÷2)=24 → α κ48+24=72.
State Machine would represent this as S0[48] → S1[÷2=24] → S2[48⊕24=72]✓.
These alternative reasoning chains were generated synthetically using a larger teacher model (Qwen3-30B-A3B), with a prompt template that has both the question and original reasoning chain5.
Abiding by standard fine-tuning practice, training took place in two stages: supervised fine-tuning (SFT) and reinforcement learning (RL). One thought I had when setting this up was that we probably want RL to form the bulk of the training, and avoid having SFT lock the model into any kind of rigidity. Alas, RL is expensive and slow, so I didn’t manage to iterate on this as much as I would like to for this experiment. For RL, I used Group Relative Policy Optimization (GRPO) with a reward function that balances correctness and reasoning efficiency:
where is the correctness score (binary for GSM8K, F1 for DROP), is the reasoning token count for a rollout, alpha is the maximum penalty parameter, is the max reasoning token parameter, and is the correctness threshold (1 for GSM8K, 0.8 for DROP). I ended up setting , and for GSM8K, for DROP.
To test whether these new reasoning schemes actually improve reasoning, I established four baseline configurations for comparison. The first set is zero-shot, that is, I evaluate Qwen3-8B out of the box without any task-specific fine-tuning. Alongside standard CoT reasoning, I also tested the zero-shot’s performance without reasoning, by forcing an empty thinking block and prompting the model to answer immediately. The second set uses SFT, and similarly two results are reported here, with vs without thinking.
Results!
| Configuration | GSM8K (%) | GSM8K Length | DROP F1 (%) | DROP Length |
|---|---|---|---|---|
| Zero-Shot Baseline | ||||
| No reasoning | 13.8 (±1.0) | — | 44.8 (±1.4) | — |
| Default CoT | 61.1 (±1.4) | 451.7 (±9.7) | 63.2 (±1.3) | 507.9 (±8.9) |
| SFT Baseline | ||||
| SFT no reasoning | 69.7 (±1.3) | — | 62.8 (±1.3) | — |
| SFT w/ standard CoT | 90.9 (±0.8) | 124.1 (±1.6) | 71.2 (±1.3) | 320.3 (±6.2) |
| SFT | ||||
| SFT w/ Cipher | 83.2 (±1.0) | 57.9 (±1.5) | 69.2 (±1.3) | 112.7 (±6.5) |
| SFT w/ State Machine | 86.7 (±0.9) | 61.7 (±1.5) | 69.4 (±1.3) | 58.2 (±2.2) |
| SFT + RL | ||||
| SFT + RL, standard CoT | 90.2 (±0.8) | 57.2 (±1.5) | 72.8 (±1.2) | 54.6 (±1.9) |
| SFT + RL, Cipher | 84.1 (±1.0) | 44.3 (±0.9) | 72.1 (±1.2) | 32.4 (±0.9) |
| SFT + RL, State Machine | 87.1 (±0.9) | 57.1 (±1.7) | 71.2 (±1.2) | 45.7 (±0.7) |
From the baselines, we can see that standard CoT without fine-tuning create the most verbose reasoning chains, with decent accuracy scores on both datasets. Standard CoT SFT boosts accuracy and shorten reasoning length considerably. With SFT only, the Cipher and State Machine schemes further compress reasoning length by 50% for GSM8K, and up to 80% for DROP, with only a slight decrease in performance compared to the SFT no-reasoning and zero-shot standard CoT baselines. For both alternative reasoning schemes, RL further improves accuracy and reasoning efficiency, albeit to a much lesser degree beyond SFT.
The most interesting result in the RL stage actually lies in the standard CoT configuration — RL alone was able to cut standard CoT’s reasoning length by roughly the same amount that our compressed reasoning models could, without significant decreases in performance. In one extreme case, the standard CoT RL model produced the most efficient reasoning trace 20+10=30, 30*3=90, while the two other models were compelled to at least present some symbols in their reasoning. Perhaps the issue all along was simply that the base model was not trained to produce efficient reasoning chains?6
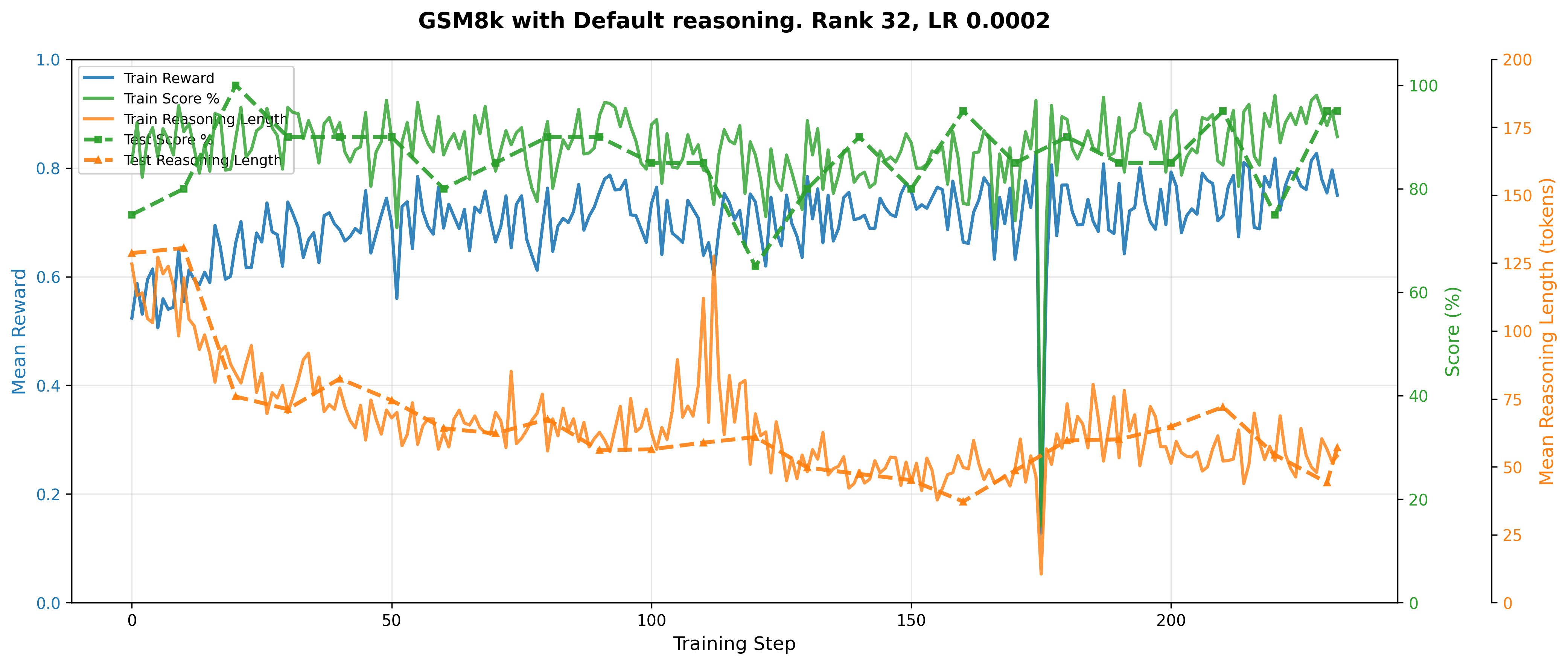
(Lastly, here's a RL training plot for standard CoT, just for fun)
Thoughts
These experiments show that chain-of-thought reasoning can be compressed without catastrophic accuracy loss. At least insofar as the reasoning demands of GSM8K and DROP are concerned, such compression can take the form of symbolic representations that, while still adhering to some kind of internal consistency and structure, are unconstrained by natural language conventions. It remains to be seen what actually drives the reasoning gains in these alternative reasoning models. Maybe there is still a direct relationship between reasoning token count and reasoning capacity, or maybe reasoning gains are unlocked upon outputting certain “keyword” tokens, like critical intermediate values in solving a math question. Perhaps one can train a linear probe to find out the specific point at which a reasoning chain improves a model’s final answer accuracy, thereby isolating some of these effects? But that’s an experiment for another day.
Simply put, an LLM “learns” to break down a complex task into a sequence of steps rather than answering a question outright. This can be implemented as a prompt at inference time e.g. telling a model to “think step-by-step”, or instilled directly into a model’s behavior during post-training. There was a time when frontier models would reveal a large portion of this intermediate logic, but this transparency has degraded over time.↩
Is this The Bitter Lesson?↩
GSM8K already has reasoning chains as part of the dataset, but DROP does not. I used Qwen3-30B to generate reasoning chains, with an F1 score filter of 0.8 to ensure correctness. To control for selection bias, care was taken to ensure that the resulting question-type distribution remained consistent, and that although the downstream model was trained on this (possibly easier) question subset, the held-out validation set was not filtered↩
Some time after this project, I came across an interesting paper which argued that GRPO systematically biases higher response lengths during training↩